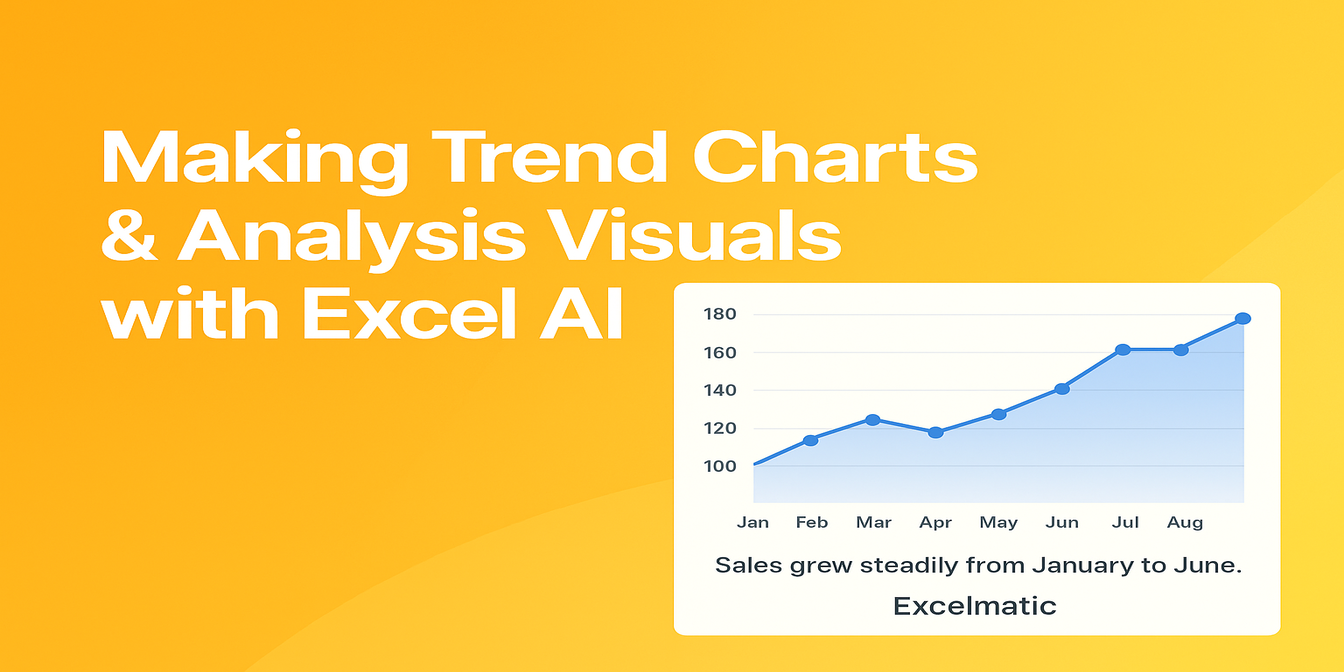
복잡한 반품 기록? 무작위적인 환불 사유? 그리고 드롭다운 메뉴에 '누락된 부품'이 서로 조금씩 다른 다섯 가지 버전으로 표시되는 문제?
하지만 엑셀을 열고 COUNTIFS 수식을 작성하며 "내일은 정리해야지"라고 다짐하는 대신, Excelmatic에 파일을 업로드하고 궁금한 점을 영어로 간단히 입력했습니다.
구문도 없고, VLOOKUP도 없었습니다. 그저 순수한 호기심과 세 가지 스마트한 프롬프트만으로 해결했습니다.
준비 과정
두 개의 간단한 시트가 있었습니다:
- 반품 기록 - 주문 번호, 제품, 반품 사유, 환불 금액, 만족도 점수(1~5점)가 포함되어 있었습니다.
- 고객 서비스 로그 - 고객 ID, 처리 시간, 문제 유형, 그리고 고객의 서비스 응답("만족", "보통" 등)이 기록되어 있었습니다.
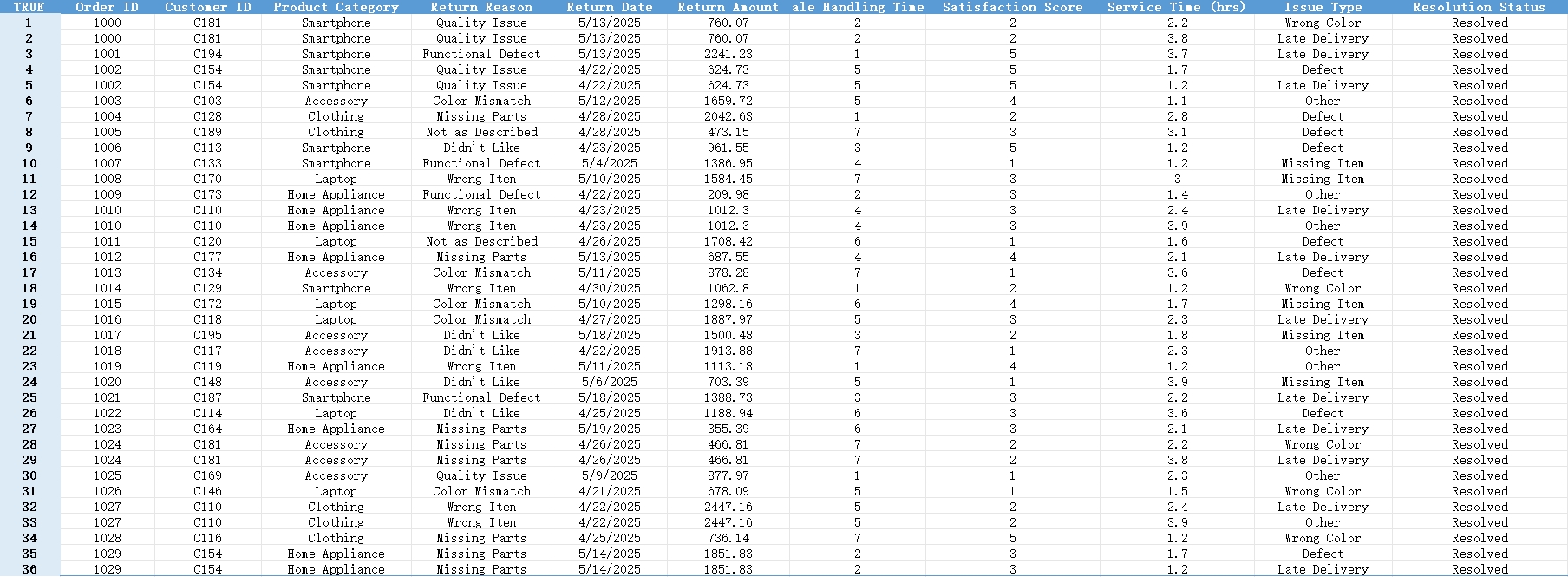
완벽하지 않았고, 깔끔하지도 않았습니다. 현실 그대로였죠.
Excelmatic에 질문한 내용
정확히 입력한 질문은 다음과 같습니다—더도 말고 덜도 말고 딱 이렇게:
1. "반품 기록에서 중복된 주문 번호가 있는지 확인하고 목록을 만들어 주세요."
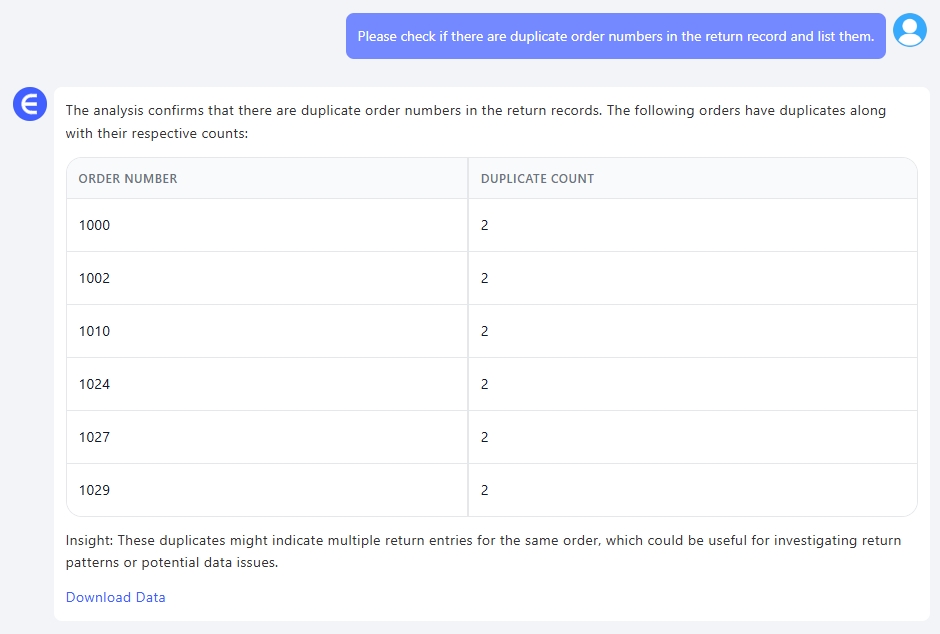
이건 제가 알지도 못했던 문제였습니다. Excelmatic이 확인을 실행하고 모든 중복된 주문 ID를 깔끔한 별도의 테이블로 정리해주었습니다.
알고 보니: 동일한 주문이 여러 번 표시된 행이 몇 개 있었습니다—같은 고객, 같은 제품, 같은 반품 사유. 아마도 누군가 "내보내기"를 두 번 누르거나 후속 조치 후 동일한 반품을 다시 기록한 것 같습니다. 1,000행이 넘는 스프레드시트에서는 눈치채기 힘든 현실적인 문제였죠.
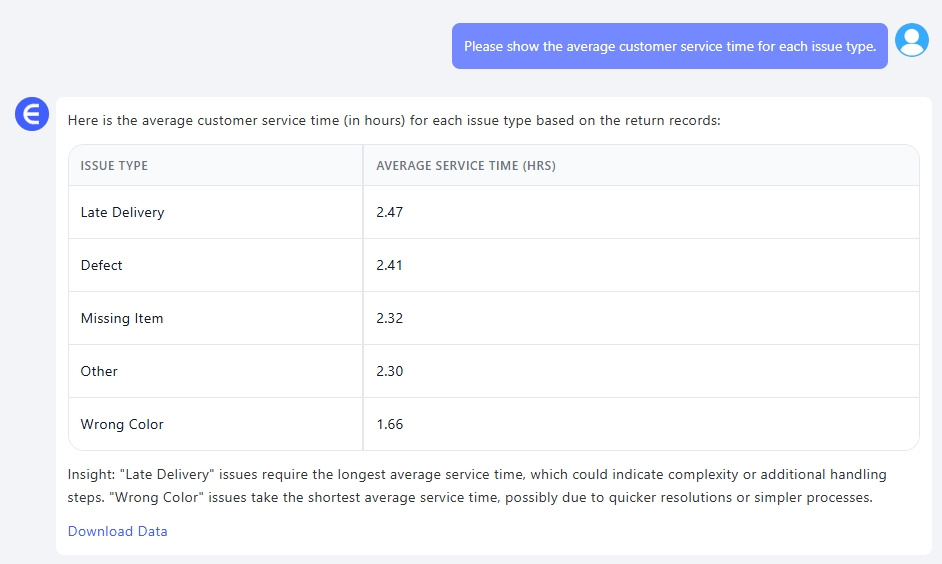
2. "각 문제 유형별 평균 고객 서비스 시간을 보여주세요." 여기서 재미가 시작됩니다. 일반적인 엑셀 작업이라면:
- 피벗 테이블 생성
- "문제 유형"을 행에 추가
- "서비스 시간"을 값에 추가
- "평균"으로 변경
- 소수점 서식 지정
- 인턴이 원본 시트를 망치지 않기를 바람
Excelmatic은 그냥 답을 알려주었습니다. 문제 유형을 그룹화하고 각각의 평균 처리 시간을 계산한 후 출력을 서식화했습니다. 마술 같지만 실용적이었죠.
3. "환불 금액별로 구분된 고객 만족도 점수 분포를 생성해주세요." 이번에는 통찰력이 있었습니다.
Excelmatic이 자동으로 그룹화된 구간(예: $0–$500, $500–$1000 등)을 생성하고 각 구간 내에서 고객이 매긴 만족도 점수를 매핑했습니다. 실제로 $2000 환불과 $300 환불의 감정적 비용을 볼 수 있었습니다.
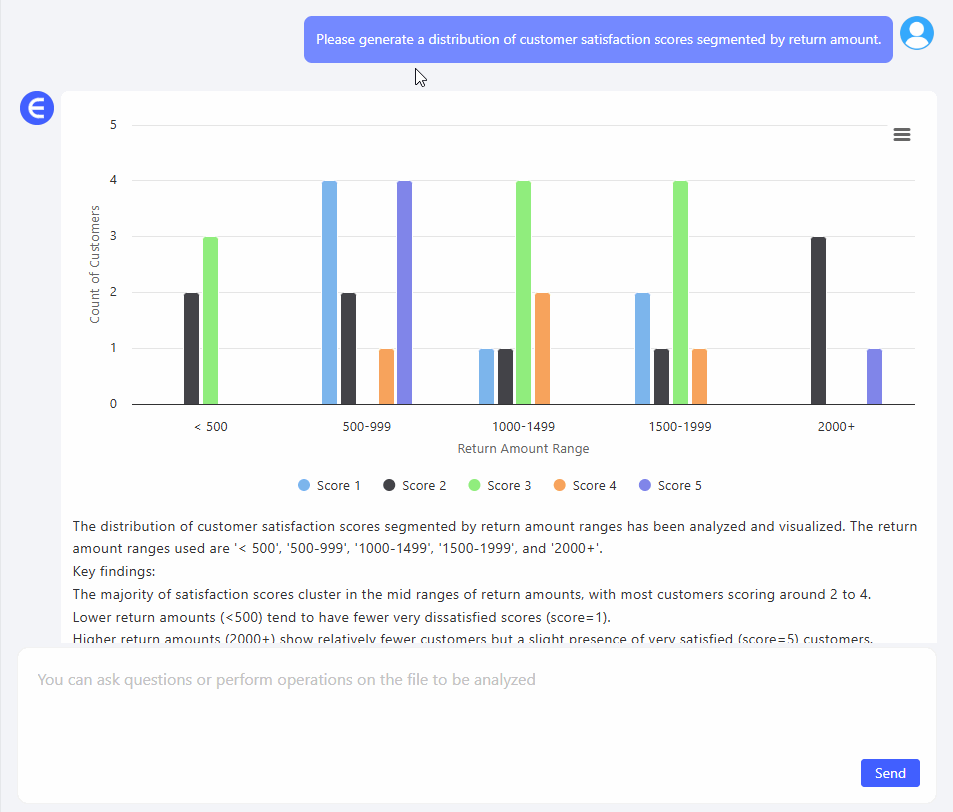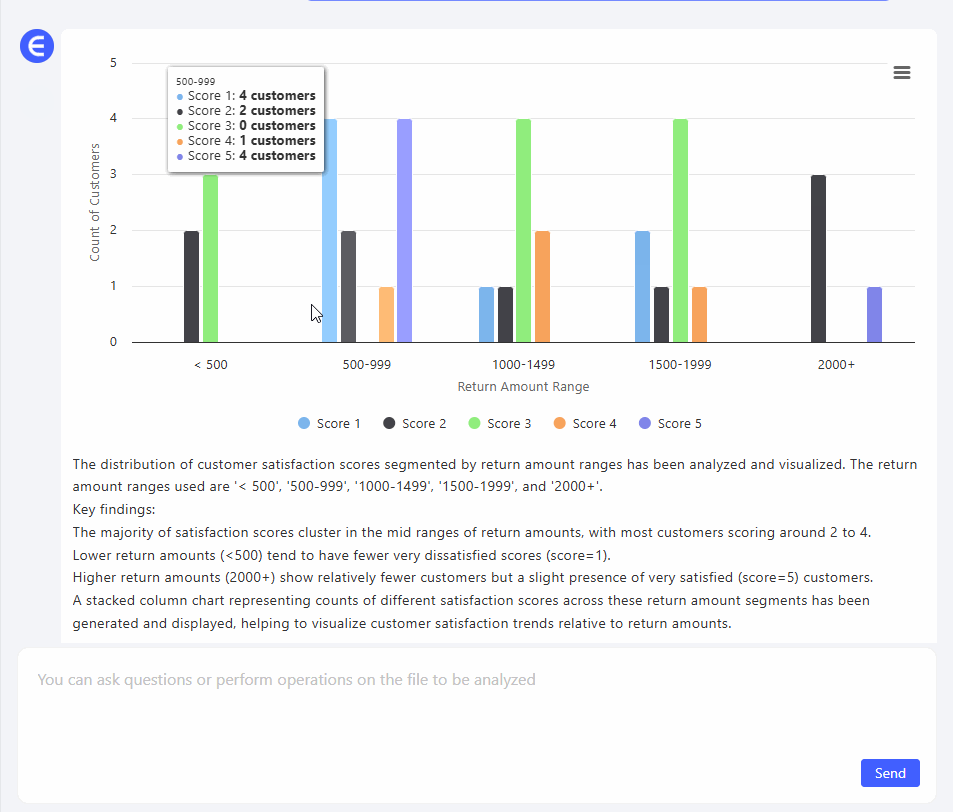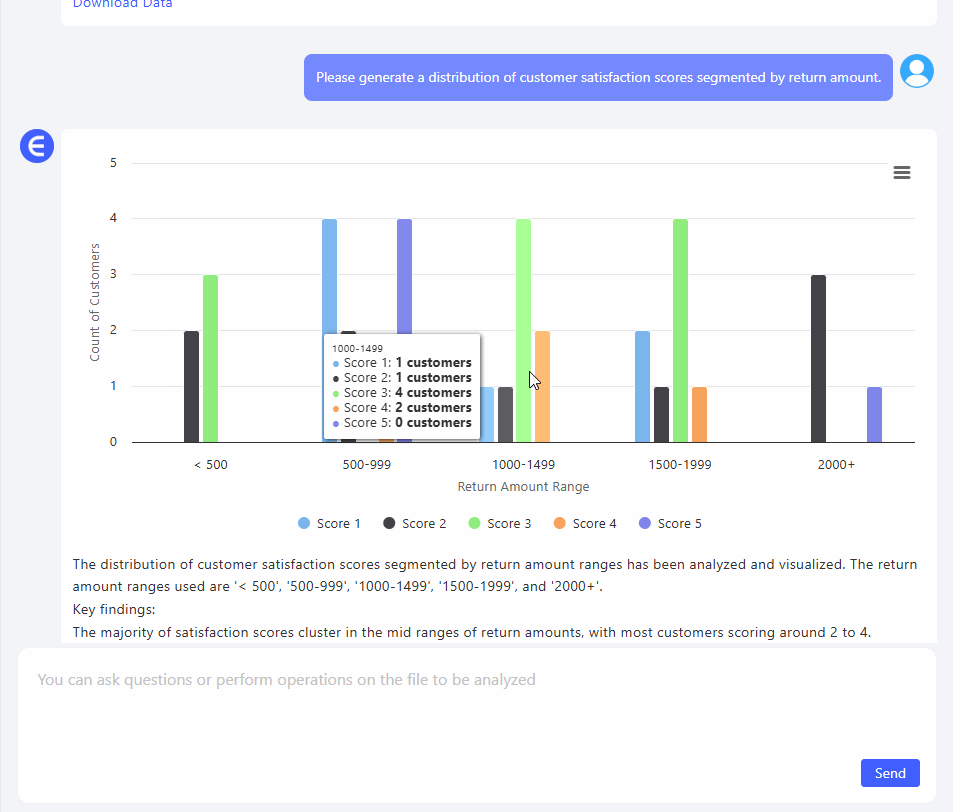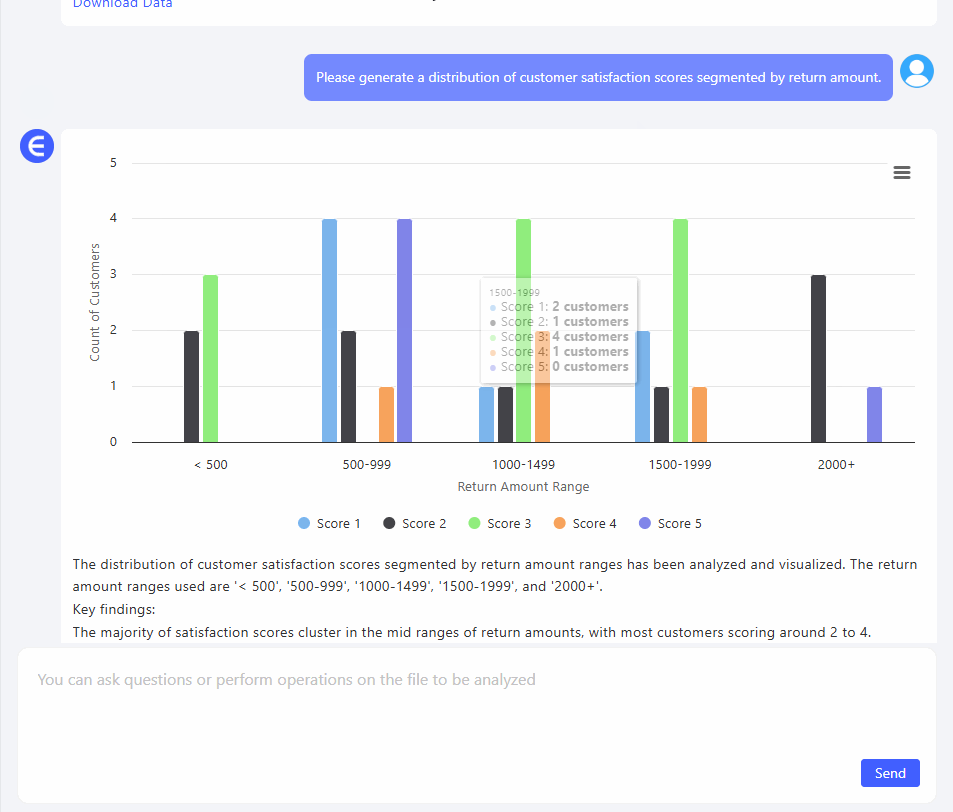
패턴은 분명했습니다: 환불 금액이 클수록 점수가 더 낮았습니다. 당연한 것 같지만, 시각화되기 전에는 그저 추측에 불과했죠.
무엇을 배웠나요?
단순히 데이터를 정리한 것이 아니라, 데이터가 말하려는 내용을 실제로 이해했습니다:
- 중복은 시간을 낭비하고 통계를 왜곡합니다
- 모든 고객 문제가 동일한 시간이 소요되는 것은 아닙니다—어떤 것은 3배 더 오래 걸립니다
- 고액 반품은 일반적으로 더 불만족스러운 고객을 의미합니다
그리고 이 모든 것을 탭 전환, 구문 검색, 또는 땀 흘리지 않고 해냈습니다.
마지막 생각
Excelmatic은 엑셀을 대체하려는 것이 아닙니다. 특히 엑셀이 주업무가 아니라 그 안의 데이터로 의사 결정을 내리는 사람들이 엑셀을 더 잘 사용할 수 있도록 돕는 것입니다.
대시보드로 가득 찬 세상에서, 그냥 질문하고 답을 얻을 수 있다는 것은 신선한 경험이었습니다.
반품 데이터가 숨기고 있는 것을 알아보고 싶으신가요? 파일을 업로드하고, 동료에게 말하듯이 입력해보세요:
👉 지금 Excelmatic을 사용해보고 직접 질문해보세요